Enterprise ETL Pipeline for ERP Data Integration — A Case Study
Transforming complex XML data from legacy ERP systems into structured, analytics-ready data using a scalable cloud ETL pipeline
TL;DR
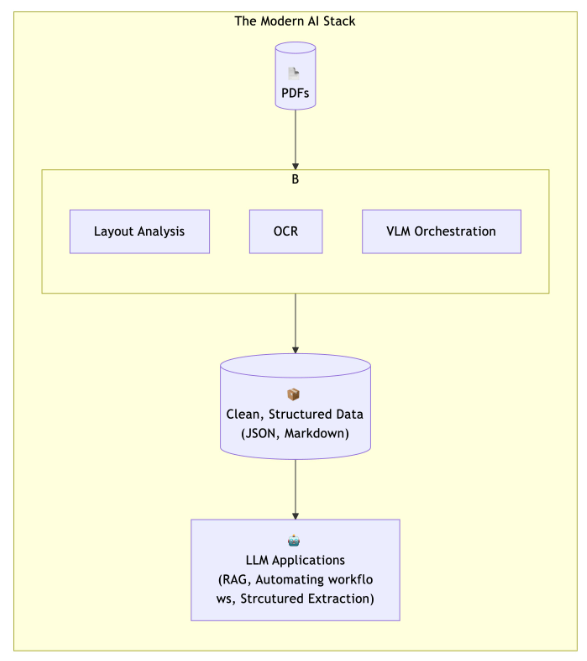
We built a scalable ETL pipeline that extracts complex XML data from enterprise ERP systems and transforms it into structured, analytics-ready formats stored in a cloud data lake. By automating ingestion, parsing deeply nested XML, and normalizing data, the system enables real-time analytics, reduces manual effort, and creates a reliable foundation for reporting and AI-driven insights.
Problem Overview
Enterprise ERP systems generate critical operational data, but accessing and using that data efficiently is a major challenge due to its complexity and format limitations.
- Data available only in XML format
- Deeply nested and complex structures
- No analytics-ready output
- Manual extraction or fragile scripts
- Limited scalability for large datasets
- Difficult to integrate with modern analytics tools
Role & Responsibilities
- Role: Full-stack data engineering team
- Responsibilities:
- Design and build the end-to-end ETL pipeline
- Develop automated data extraction from ERP APIs
- Build robust XML parsing and transformation engine
- Design schema normalization and data structuring logic
- Implement scalable cloud storage architecture
- Ensure fault tolerance, retry mechanisms, and monitoring
- Enable downstream analytics and reporting integrations
- Deploy and manage pipeline in cloud environment
Project Context
- Industry: Logistics, Supply Chain, Enterprise Data Systems
- Purpose: Transform ERP XML data into structured, analytics-ready datasets for reporting, analytics, and future AI use cases
- Constraints: XML data is deeply nested and inconsistent, requiring robust parsing and transformation. The system must scale for large volumes, ensure reliability, and support real-time or scheduled processing.
My Approach
We approached this as a data transformation and scalability problem rather than just data extraction. The focus was on building a pipeline that not only processes XML but converts it into a reliable, structured data foundation for analytics.
- Pipeline-first architecture: Designed a complete ETL flow from extraction to consumption
- Schema-aware parsing: Built intelligent parsing for deeply nested XML
- Normalization strategy: Standardized data across inconsistent ERP outputs
- Cloud-first storage: Organized data lake with raw and processed layers
- Automation and reliability: Implemented scheduling, retries, and monitoring
Research & Insights
Key Findings from Discovery
- ERP systems store valuable data but in non-analytics-friendly formats
- XML complexity is a major barrier to data usability
- Manual extraction processes are inefficient and error-prone
- Organizations lack scalable pipelines for continuous data processing
- Structured data is critical for analytics and decision-making
Competitive Research
- Most solutions offer basic extraction without deep transformation
- Limited support for complex XML parsing
- Lack of scalable cloud-based architectures
- No structured pipeline for analytics-ready outputs
User Persona
- Name: Sarah
- Role: Data Analyst
- Goals: Access structured ERP data for analytics and reporting
- Pain Points: Complex XML data, manual processing, lack of reliable datasets
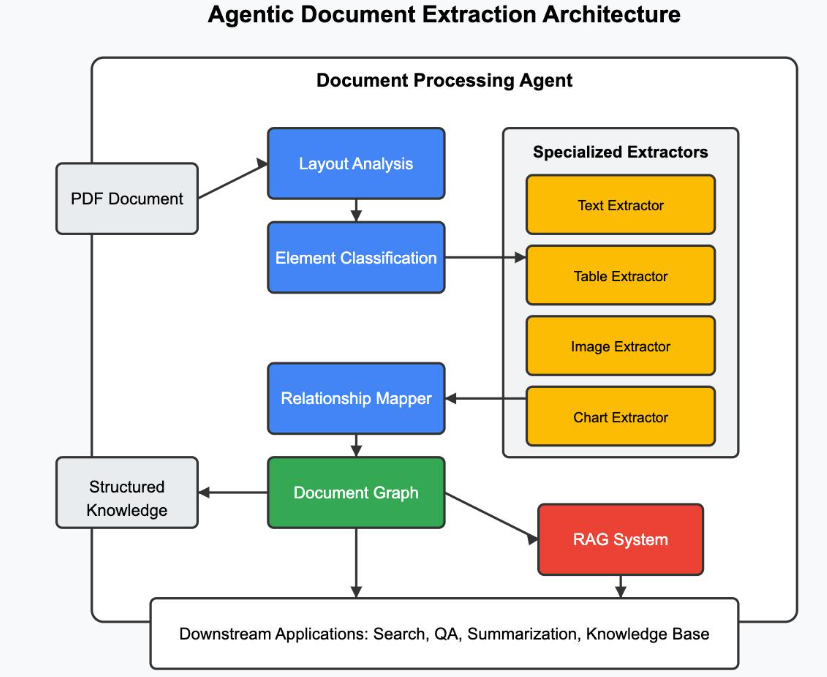
Information Architecture
- Data Extraction Layer — fetches XML data from ERP APIs
- Ingestion Layer — handles scheduling and queue-based ingestion
- Parsing Engine — processes deeply nested XML structures
- Transformation Layer — converts XML into structured JSON
- Storage Layer — stores data in cloud data lake (raw + processed)
- Consumption Layer — enables analytics, dashboards, and reporting
Visual Language
The system emphasizes clarity in data flow and structured storage. The architecture is designed for scalability, traceability, and ease of integration with analytics tools, ensuring clean and organized data layers.
Wireframes & Early Ideas
Initial exploration focused on designing the ETL pipeline flow, parsing strategies for XML, and structuring the data lake. Early validation ensured accurate transformation before integrating analytics layers.
Designing Solutions
Problem: XML data is complex and deeply nested
- Built a robust XML parsing engine
- Handled deep nesting and repeating nodes
Problem: Inconsistent data structures
- Implemented schema normalization layer
- Standardized data for analytics readiness
Problem: Lack of scalable storage
- Designed cloud data lake with raw and processed layers
- Enabled versioning and traceability
Problem: Pipeline reliability
- Implemented fault tolerance, retries, and logging
- Ensured continuous and stable processing
Problem: Manual and slow processing
- Automated pipeline with scheduling and incremental updates
Tech & Implementation
- Backend: Node.js (ETL services)
- Data Processing: Custom XML parsers
- Storage: AWS S3 (data lake)
- Scheduling: Cron / job schedulers
- Integration: ERP APIs
Real-world Features & Highlights
- Automated XML data ingestion
- Complex XML parsing engine
- Data transformation to structured formats
- Cloud data lake storage
- Fault-tolerant processing
- Scheduled and incremental data updates
- Analytics-ready datasets
Results & Impact
- Eliminated manual data extraction
- Faster data availability for analytics
- Improved data reliability and consistency
- Enabled scalable data processing
- Foundation built for analytics and AI use cases
Challenges & Learnings
- Handling inconsistent XML structures required flexible parsing logic
- Balancing performance and accuracy in large datasets
- Ensuring fault tolerance in distributed processing
- Designing scalable storage architecture for long-term growth
Takeaways
- Data transformation is more valuable than extraction
- Scalable pipelines are essential for enterprise data
- Structured data unlocks analytics and AI potential
- Automation is key to operational efficiency
Next Steps
- Real-time streaming data pipelines
- Advanced analytics and dashboards
- Integration with BI tools
- AI/ML model integration
Client Feedback
"This ETL pipeline unlocked the true value of our ERP data. What was once difficult to access is now structured, reliable, and ready for analytics. It has significantly improved our decision-making capabilities."
— ERP Data Integration Client
Call to Action
If your organization is struggling to utilize ERP data effectively, contact WhizCloud — we can help you build a scalable ETL pipeline tailored to your needs.
Contact Us