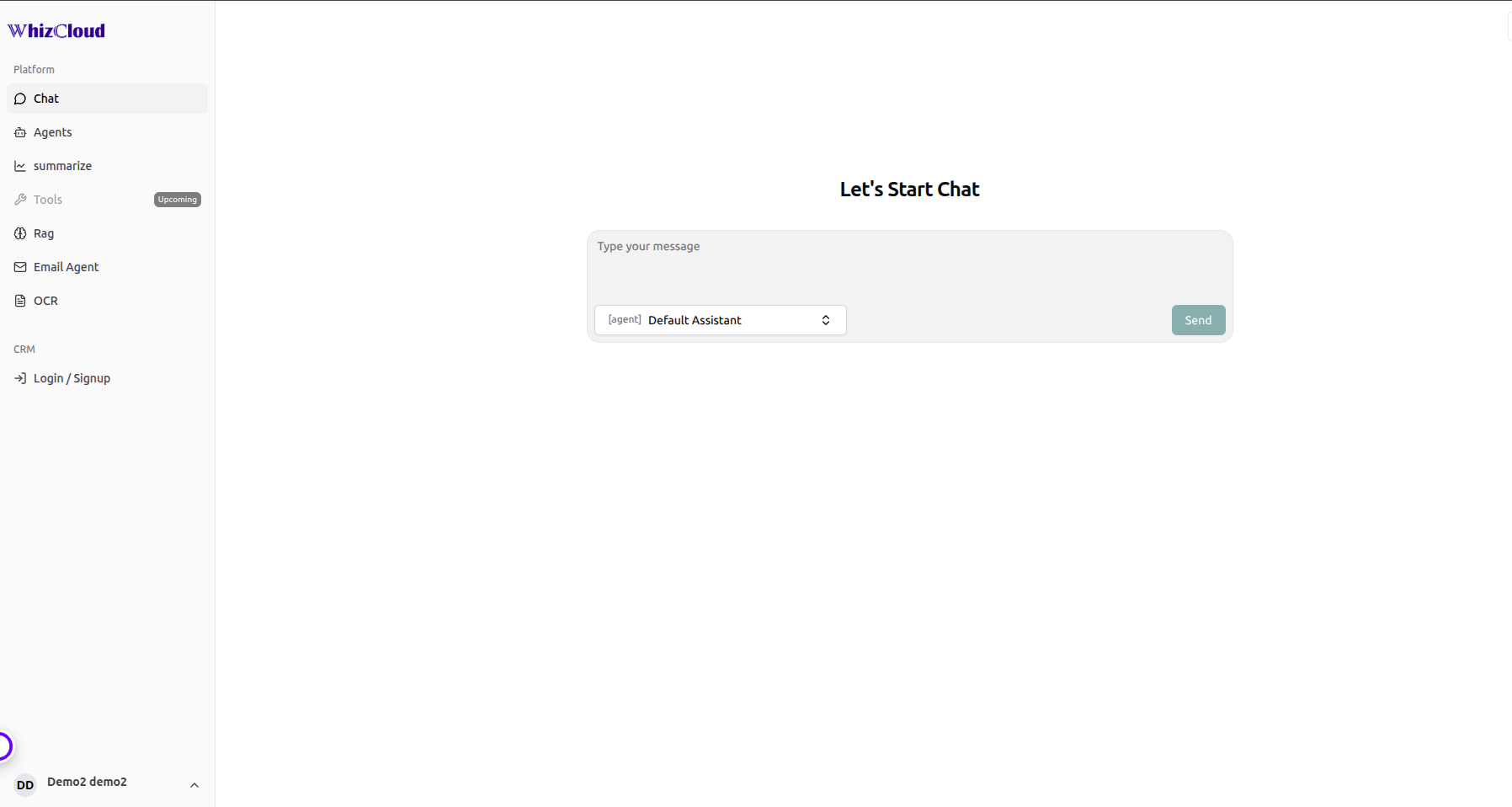
Enterprise AI Marketplace — A Case Study
Building a scalable multi-agent intelligence platform with LangGraph, RAG, and Qdrant for enterprise knowledge access and automation
TL;DR
We built LangGraph-RAG, an enterprise AI marketplace where multiple domain-specific AI agents — HR, Finance, Support, Operations — each maintain their own knowledge base and serve contextually accurate responses on demand. Using LangGraph orchestration, Qdrant vector search, Google Gemini, NestJS microservices, and React.js, the platform transforms fragmented enterprise data — documents, emails, scanned files — into a unified conversational intelligence layer. The result: information retrieval reduced from hours to seconds, manual document processing and email analysis automated, and a scalable multi-agent foundation that grows with the organisation without requiring new infrastructure for each domain.
Problem Overview
In data-driven enterprises, knowledge is abundant but accessing it efficiently remains a persistent challenge. Critical information is scattered across documents, emails, internal systems, and department-specific repositories — leading to delays, inconsistencies, and missed opportunities. Traditional search tools lack contextual understanding, and a single generalised AI model cannot serve the accuracy demands of multiple distinct business domains simultaneously.
- Knowledge silos across departments — HR, Finance, Support, and Operations all held separate, inaccessible information stores
- Manual document search was time-consuming and returned results without contextual relevance
- Traditional search tools could not understand intent or retrieve meaningfully related content
- No way to scale AI solutions across multiple domains without duplicating infrastructure and effort
- Emails and unstructured data — scanned documents, images, PDFs — were entirely outside any intelligent retrieval system
- A single generalised AI model produced generic, low-trust responses that did not account for enterprise-specific context
Role & Responsibilities
- Role: Full-stack AI engineering team
- Responsibilities:
- Design and build the full multi-agent AI platform — orchestration engine, vector layer, conversation service, and web frontend
- Implement the LangGraph orchestration engine for workflow execution, multi-step reasoning, and agent coordination
- Build the Qdrant vector intelligence layer for semantic embedding storage and similarity search
- Develop the agent management service for creating, configuring, and mapping knowledge bases to specific agents
- Build the OCR and document intelligence service for extracting and processing scanned documents and images
- Integrate the email intelligence service with Gmail for automated email analysis, summarisation, and insight extraction
- Develop the conversation service with real-time messaging, session management, and history tracking
- Implement JWT authentication, RBAC access control, and secure password handling
- Deploy the full platform on Docker and Kubernetes with CI/CD pipelines and managed cloud infrastructure
Project Context
- Industry: Enterprise AI — knowledge management, intelligent automation, and multi-domain intelligence
- Purpose: Transform fragmented enterprise knowledge into a unified conversational intelligence layer — accessible on demand, domain-accurate, and scalable across departments without new infrastructure per domain
- Constraints: Responses had to be grounded in real enterprise data to be trusted — hallucination was not acceptable in HR, Finance, or Support contexts. Each domain agent needed an independent knowledge base while sharing a single platform. Unstructured data — scanned documents, emails, images — had to be made queryable. The system had to be deployable in cloud or hybrid environments with enterprise-grade security.
My Approach
We designed the platform around a marketplace mental model — each AI agent is a specialised service provider with its own domain expertise and knowledge base, rather than a single generalised model trying to serve all needs at once. The RAG pipeline was established as the core accuracy mechanism before any agent-specific work began, ensuring every response was grounded in retrieved enterprise data rather than model training alone. The LangGraph orchestration layer was built to coordinate multi-step reasoning across agents and pipelines without tight coupling between services.
- Marketplace architecture: Designed domain-specific agents as independent services — each with its own vector collection, knowledge base, and configuration — before building any shared layer
- RAG pipeline first: The retrieval-augmented generation flow — query → embed → semantic search → context retrieval → LLM generation — was validated end-to-end before agent specialisation was introduced
- Unstructured data coverage: OCR and email intelligence were scoped as first-class services, not afterthoughts — enterprise data lives in scanned documents and inboxes, not just clean PDFs
- Microservices design: Each core capability (orchestration, vector search, agent management, conversation, OCR, email) was built as an independently deployable service for flexibility and scaling
Research & Insights
Key Findings from Discovery
- A single AI model serving all departments produced responses that were too generic to be acted on — domain specificity was the primary driver of user trust
- The majority of enterprise knowledge lived in unstructured formats — scanned PDFs, email threads, Word documents — none of which was accessible to standard search
- Employees abandoned search tools quickly when results required further manual filtering — contextual accuracy at the first result was critical to adoption
- Email analysis was consuming significant manual effort across Support and Operations teams — a high-value automation target with immediate measurable return
- Departments needed to manage their own knowledge bases without IT involvement — the agent configuration layer had to be admin-accessible, not developer-dependent
Competitive Research
- Most enterprise knowledge tools offered a single search interface over a unified document store — none offered per-domain agent specialisation with independent knowledge bases
- RAG implementations at the enterprise level were typically custom-built for one use case — no marketplace-style platform existed that let organisations deploy and scale multiple domain agents from a single system
- Email and OCR intelligence were available as standalone tools but not integrated into a conversational AI layer — the combination in one platform was a clear differentiator
User Persona
- Name: Rohit
- Role: HR Manager at a mid-sized enterprise
- Goals: Give employees instant, accurate answers to policy questions without routing every query through the HR team; reduce time spent searching internal documents; get email summaries and action items without reading every thread
- Pain Points: Policy documents spread across SharePoint, email, and printed manuals; generic AI responses that don't reflect company-specific rules; no way to query scanned onboarding documents or historical email threads
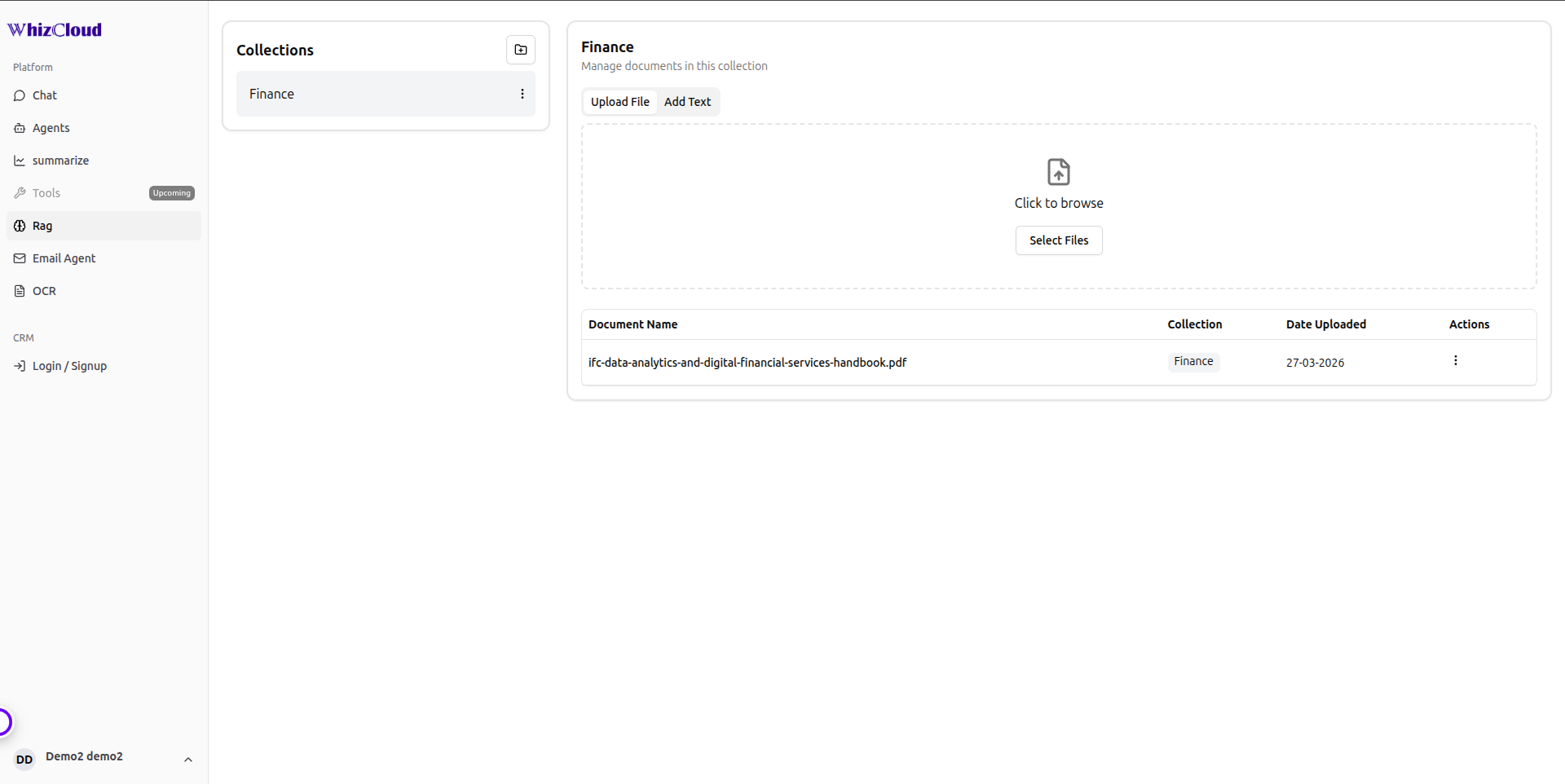
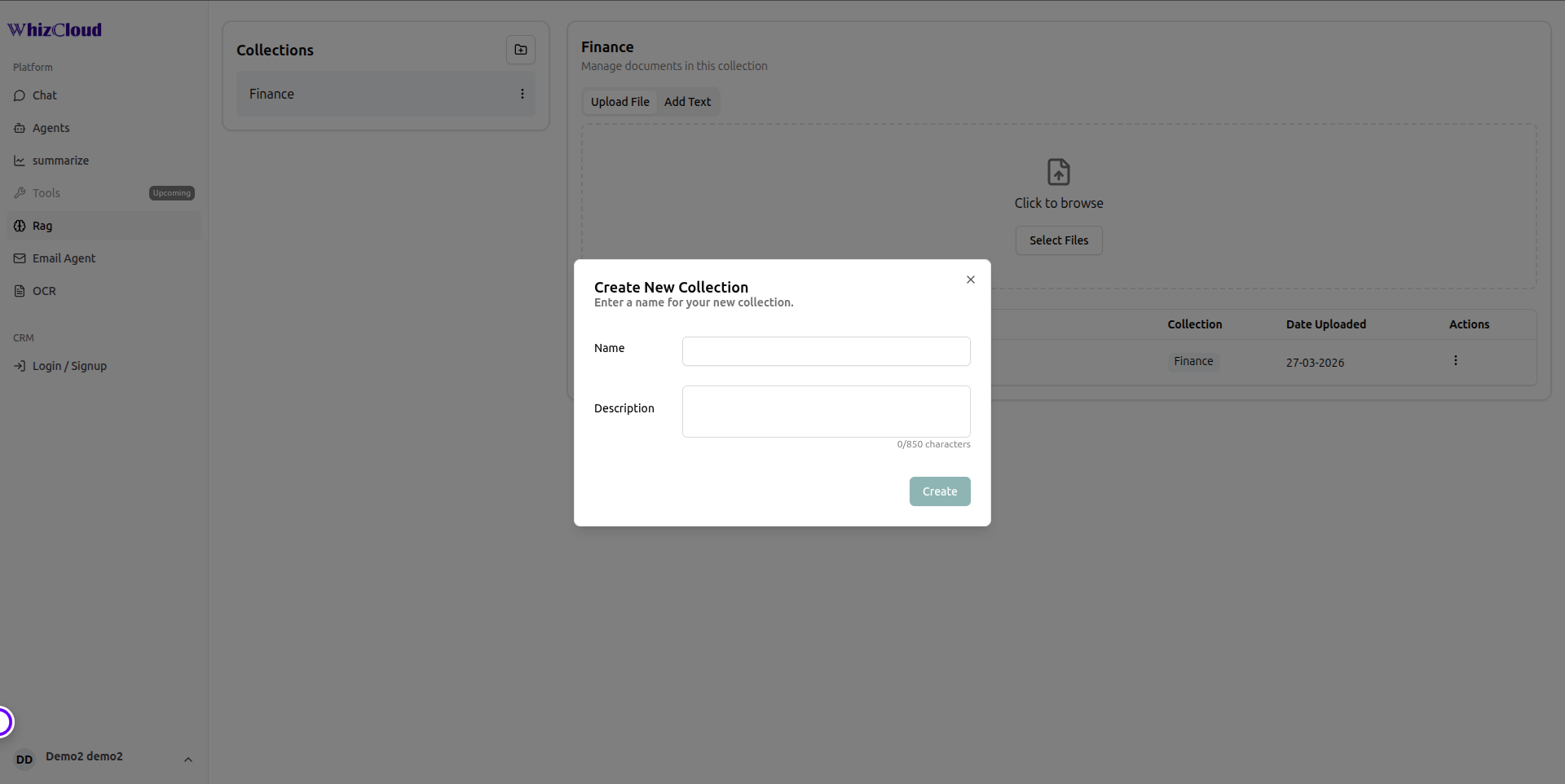
Information Architecture
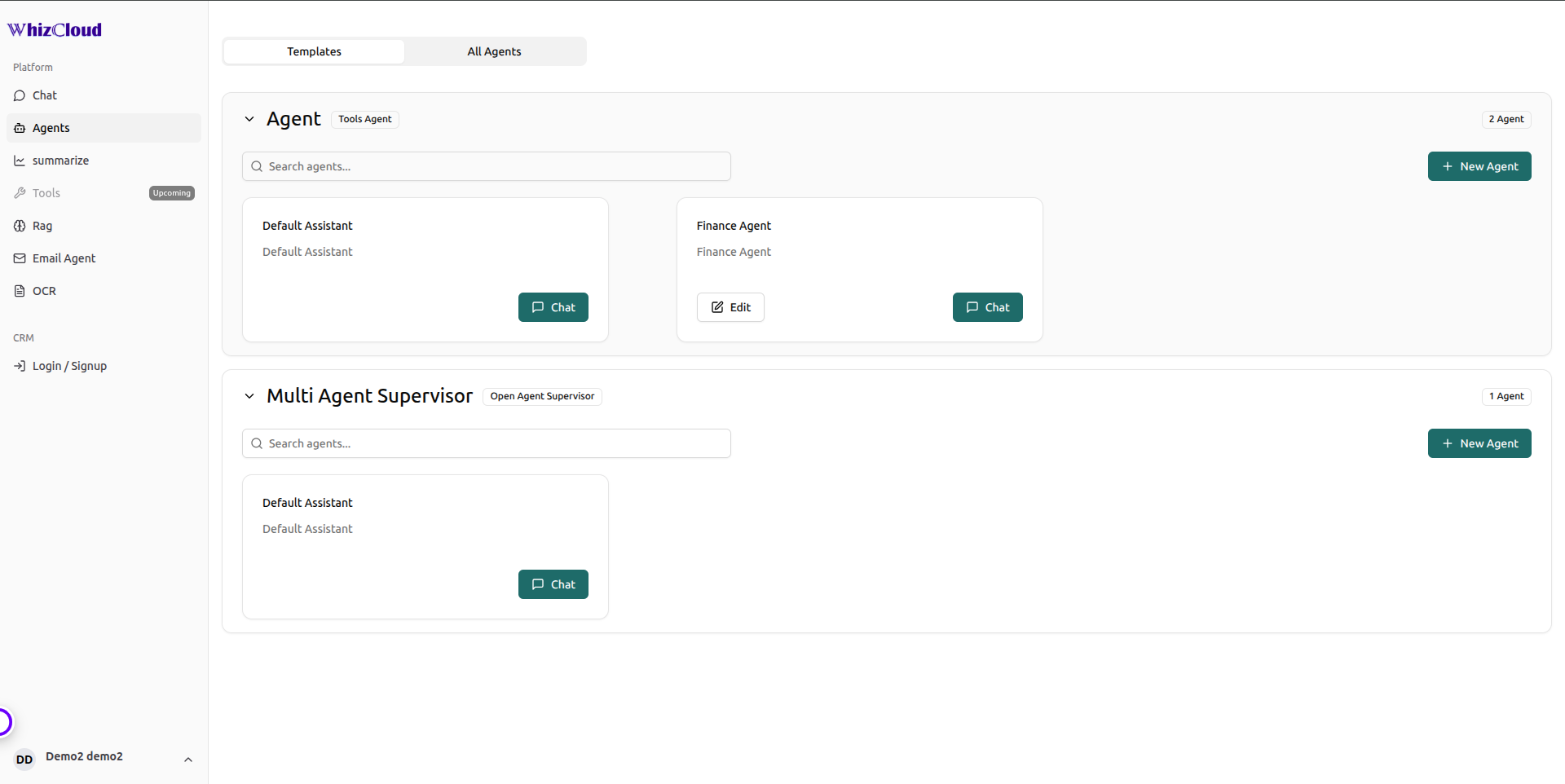
- Multi-Agent Marketplace — domain-specific AI agents (HR, Finance, Support, Operations) each with independent knowledge bases and vector collections, plus a Global Intelligence Agent for cross-domain fallback
- LangGraph Orchestration Engine — workflow execution, multi-step reasoning, and agent coordination across pipelines
- Vector Intelligence Layer (Qdrant) — embedding storage, semantic similarity search, and per-agent vector collection management
- RAG Pipeline — query → embed → semantic search → context retrieval → LangGraph processing → Gemini response generation, delivered in real time
- Knowledge Management — upload and manage documents (PDF, DOCX, TXT), automatic indexing into vector collections per agent
- OCR & Document Intelligence Service — converts scanned documents and images into searchable, queryable content
- Email Intelligence Service — Gmail integration for automated email reading, summarisation, and key insight and action item extraction
- Conversation Service — real-time chat sessions, multi-agent interaction support, and full history tracking
- Agent Management Service — admin interface for creating, configuring, and mapping knowledge bases to specific domain agents
- Security Layer — JWT authentication, RBAC-based access control, bcrypt password encryption, API rate limiting
Visual Language
The conversational interface was built in React.js — designed for speed and clarity, supporting simultaneous interaction with multiple agents from a single screen. The layout prioritises the conversation above all else, with agent selection and knowledge context visible but not dominant. The admin interface for agent configuration and knowledge base management was designed for non-technical users — adding documents, mapping knowledge bases to agents, and monitoring agent activity are all achievable without developer involvement. The real-time response streaming experience was particularly important — users needed to see responses appearing progressively rather than waiting for a full response to complete.
Wireframes & Early Ideas
Early wireframes tested two primary flows — the user conversation interface and the admin agent configuration panel. The agent selection mechanism went through several iterations: a sidebar list, a dropdown, and ultimately a marketplace-style card grid that made the "choose your expert" mental model immediately clear. The knowledge upload and indexing flow was prototyped early to validate the document-to-vector pipeline before the UI was built around it. The email intelligence integration was the most complex to wireframe — summarising email threads and surfacing action items in a conversation context required a purpose-built rendering pattern distinct from standard document query responses.
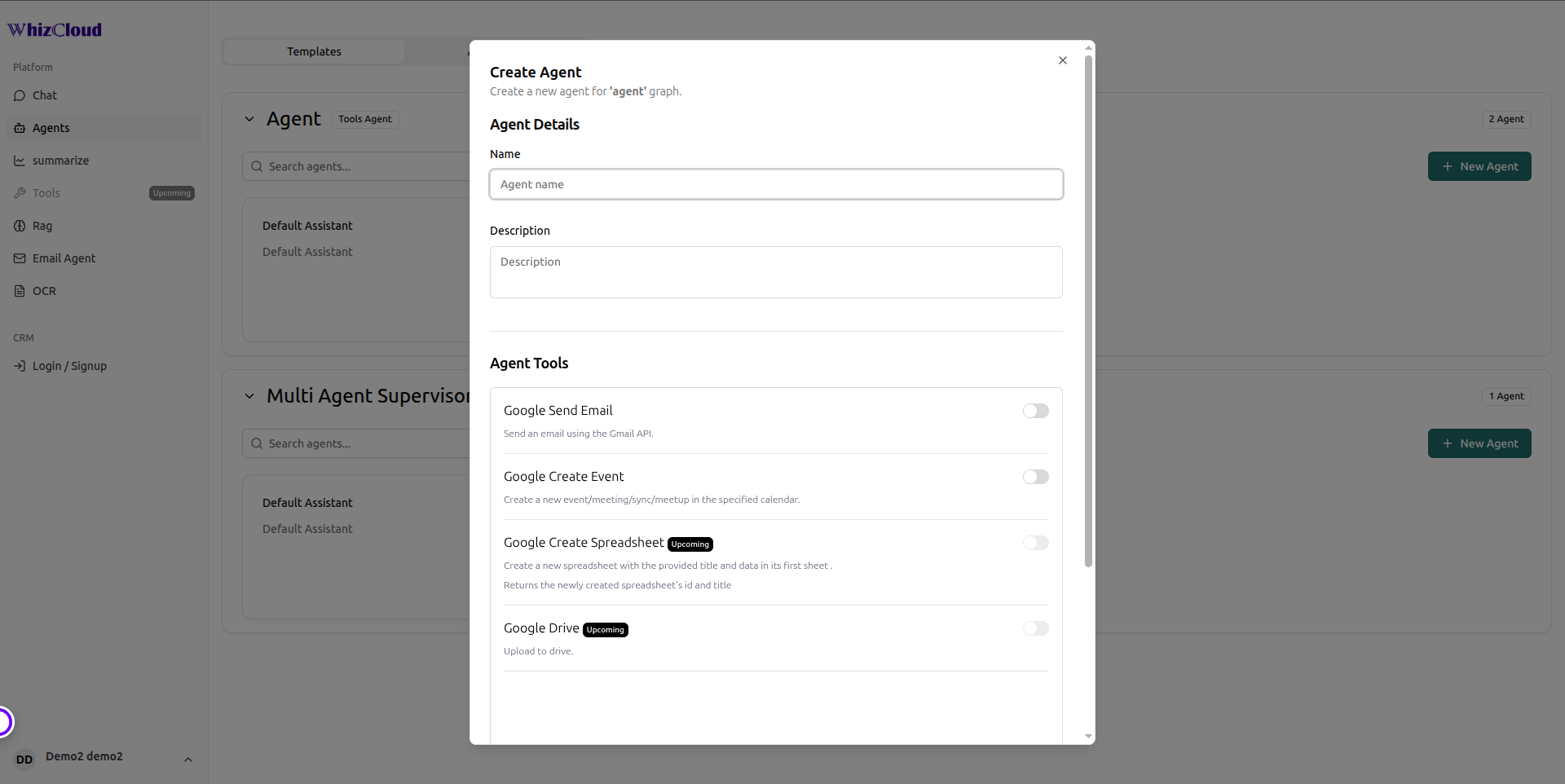
Designing Solutions
Problem: A single AI model produced generic, low-trust responses across all enterprise domains
- Designed a marketplace architecture where each domain (HR, Finance, Support, Operations) has its own dedicated AI agent with an independent Qdrant vector collection and knowledge base
- Responses are grounded in domain-specific retrieved context — the HR agent only searches HR documents, the Finance agent only searches Finance data — eliminating cross-contamination and improving accuracy
- A Global Intelligence Agent handles cross-domain and general queries as a fallback, ensuring no query goes unanswered
Problem: Enterprise knowledge was scattered across documents, scanned files, and emails — none of it queryable
- Built an intelligent knowledge layer where admins upload documents (PDF, DOCX, TXT) and they are automatically indexed into the relevant agent's Qdrant vector collection
- OCR and Document Intelligence Service converts scanned documents and images into searchable, embeddable content — making physical and legacy documents part of the conversational knowledge base
- Email Intelligence Service integrates with Gmail to automatically read, summarise, and extract key insights and action items from email threads — reducing manual communication analysis effort across Support and Operations teams
Problem: Traditional search returned results without contextual relevance or reasoning
- Built a full RAG pipeline — user query is converted to embeddings, semantic similarity search is performed against the agent's Qdrant collection, relevant context is retrieved, processed through LangGraph pipelines, and Google Gemini generates a contextually grounded response
- Responses are grounded in real enterprise data — hallucination is structurally minimised because the LLM reasons over retrieved facts, not training memory alone
- LangGraph orchestration enables multi-step reasoning — complex queries that require synthesising information from multiple retrieved documents are handled within a single coherent pipeline
Problem: Scaling AI to new departments required new infrastructure and engineering effort each time
- The agent management service lets admins create new domain agents, upload knowledge documents, and configure vector collection mappings through the admin interface — no developer involvement needed
- Each new agent shares the same orchestration, retrieval, conversation, and security infrastructure — only the knowledge base and configuration differ
- REST APIs expose all agent capabilities for external integration — enterprise workflows, Slack, and third-party systems can connect without custom development
Tech & Implementation
- Orchestration: LangGraph — workflow execution, multi-step reasoning, and agent coordination across the full RAG pipeline
- Vector database: Qdrant — high-performance embedding storage and semantic similarity search, with independent collections per domain agent
- LLM: Google Gemini — final response generation grounded in retrieved enterprise context
- Backend: NestJS microservices — modular, independently deployable services for orchestration, agent management, conversation, OCR, email, and API gateway
- Database: MySQL via managed cloud service (AWS RDS) — structured data for users, agents, sessions, and configuration
- Frontend: React.js — real-time conversational interface with multi-agent interaction support
- OCR: Document intelligence service for converting scanned documents and images into indexed, queryable content
- Email: Gmail integration for automated email reading, summarisation, and action item extraction
- Authentication: JWT-based auth, RBAC access control, bcrypt password encryption, API rate limiting
- Containerisation: Docker — all backend microservices packaged into containers
- Orchestration (infra): Kubernetes — container orchestration with load balancing and horizontal scaling
- Frontend deployment: Vercel or AWS S3 + CloudFront — CDN delivery for the React.js interface
- CI/CD: Git-based repositories with automated build, test, and deployment pipelines
- Monitoring: Observability tooling for latency tracking, query performance, and issue detection
Real-world Features & Highlights
- Multi-agent marketplace → domain-specific agents (HR, Finance, Support, Operations) each with independent knowledge bases and Qdrant vector collections
- RAG pipeline → query → embed → semantic search → context retrieval → LangGraph → Gemini response — grounded in real enterprise data
- OCR & document intelligence → scanned documents and images converted into searchable, conversational knowledge
- Email intelligence → Gmail integration for automated summarisation and action item extraction across email threads
- Semantic search → Qdrant-powered similarity search returns contextually relevant results, not keyword matches
- Global Intelligence Agent → cross-domain fallback ensuring no query goes unanswered
- Admin knowledge management → upload documents, configure agents, and map knowledge bases without developer involvement
- Real-time conversation → multi-agent chat with session history, streaming responses, and fast contextual delivery
- API-first design → REST APIs expose all capabilities for Slack, Teams, CRM, and enterprise workflow integration
- Enterprise-grade security → JWT auth, RBAC, bcrypt, rate limiting, HTTPS, and environment-based configuration
Results & Impact
- Information retrieval time reduced from hours to seconds — employees get accurate, domain-specific answers in a single conversational query
- Manual document processing and email analysis automated — Support and Operations teams freed from repetitive information extraction tasks
- Hallucination structurally minimised — RAG grounding means responses are based on retrieved enterprise data, not model guesswork
- New AI domains deployable without engineering effort — admin-configurable agent creation scales the platform across departments without new infrastructure
- Scanned and unstructured data made conversational for the first time — OCR integration brings legacy and physical documents into the intelligence layer
- Connected intelligence ecosystem delivered — HR, Finance, Support, and Operations each have dedicated, trusted AI expertise accessible on demand
Challenges & Learnings
- Vector collection management at scale — maintaining independent Qdrant collections per agent while keeping retrieval fast required careful indexing strategy and query optimisation per domain
- RAG accuracy vs. recall trade-off — tuning the semantic search to retrieve enough context for complex queries without introducing irrelevant documents required significant iteration on embedding models and similarity thresholds
- OCR quality variation — scanned documents varied significantly in quality, font, and layout; building a robust extraction pipeline that produced clean, embeddable text across all input types required careful pre-processing
- Email intelligence scope — deciding what constitutes a meaningful insight or action item from an email thread — versus noise — required a dedicated extraction pipeline rather than a generic summarisation call
- LangGraph multi-step complexity — orchestrating multi-step reasoning across agent pipelines while keeping latency acceptable required careful pipeline design and response streaming to maintain a responsive user experience
Takeaways
- Domain specificity is the foundation of AI trust: A single generalised model will never earn the confidence of a Finance team that needs precise regulatory answers — the multi-agent marketplace model is the right architecture for enterprise AI at scale
- RAG is not optional in enterprise contexts: Grounding every response in retrieved enterprise data is the structural answer to hallucination — it is not a feature, it is the prerequisite for trustworthy AI in any business-critical domain
- Unstructured data is where the value hides: The most impactful wins came from making scanned documents and email threads queryable — that is where knowledge was trapped, and OCR and email intelligence unlocked it
- Admin configurability drives platform scale: Building agent creation and knowledge management as admin-accessible tools meant the platform could expand to new departments without any engineering involvement — that independence multiplied the platform's value
- Microservices pay off in AI platforms: Each service — orchestration, vector search, OCR, email, conversation — evolving independently meant improvements to one did not risk destabilising others, and each could be scaled to its own demand profile
Next Steps
- Voice-enabled conversational interface — query any agent by voice for hands-free knowledge access
- Multi-language support — serve global enterprise teams in their own language without forking the platform
- Advanced analytics dashboards — query volume, agent usage, retrieval accuracy, and response quality metrics per domain
- Integration with enterprise tools — Slack, Microsoft Teams, Salesforce, and HubSpot connectors for in-workflow AI access
- Continuous learning pipelines — adaptive feedback loops that improve retrieval accuracy based on user interactions over time
- Two-factor authentication and GDPR tooling — for regulated industry and enterprise compliance requirements
Client Feedback
"WhizCloud built something we had been unable to find off the shelf — a platform where each department gets its own intelligent assistant, grounded in our actual data, with responses we can trust. The HR agent alone has transformed how employees access policy information. The email intelligence capability was an unexpected highlight — our Support team's time spent on communication analysis dropped significantly within the first month. The WhizCloud team understood the architecture requirements deeply and delivered a platform that scales with us, not against us."
— Enterprise AI Marketplace Client
Call to Action
If you are looking to build an enterprise AI platform, knowledge management system, or multi-agent intelligence layer for your organisation, contact us at WhizCloud — we'd love to partner with you.
Contact Us